最近在看一些graph embedding 相关,先从node2vec入手的,在这里大概记录一下一些理解和实践。
Theory
看到embedding,第一眼就容易想到2013年Tomas Mikolov的embedding开山之作word2vec,一开始主要是用于NLP领域,基于语料库中句子序列中词与词的共现关系,来学习词的向量表征,后来大家发现不仅是NLP,在其他领域只要我们能用item构造出合理的序列,同样可以基于item之间的共现关系来学习item的向量表征,而graph embedding的大部分工作,其实就是如何构造合理的序列。
在KDD 2014上提出的DeepWalk算法,就是graph embedding 基于word2vec的一次尝试,给定一个节点,然后随机采样当前节点邻居节点中的一个来作为下一个节点,重复此过程直至采样期望长度的序列,最后使用word2vec中的skipgram模型来训练得到节点的向量。node2vec算法则是在KDD 2016上提出,是基于DeepWalk算法的一种改进,核心思想就是用一个有偏的随机游走来替代DeepWalk当中的随机游走。给定当前的节点,首先基于所有边的权重来计算出访问下一个节点的概率,然后再加入两个超参数p和q来控制游走的策略。
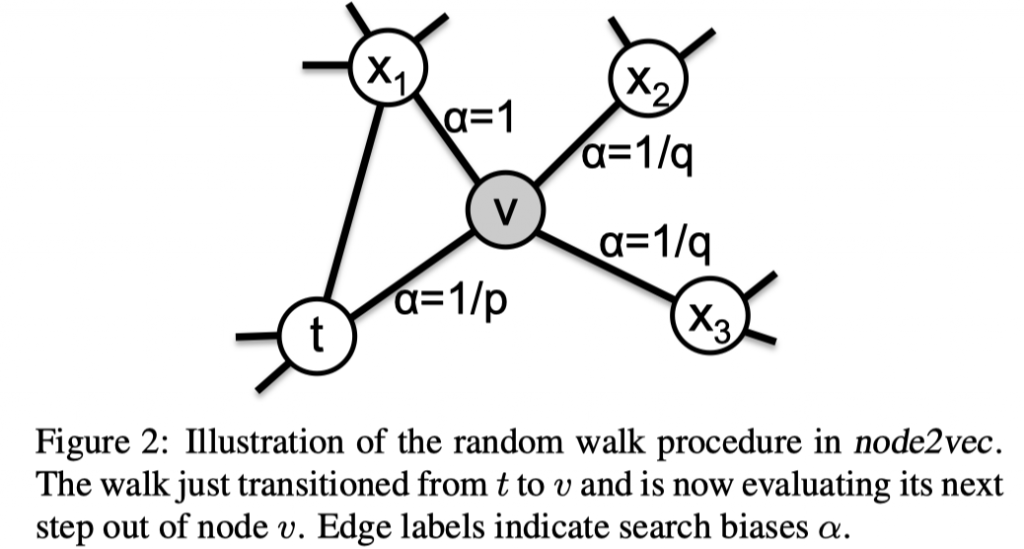
如上图所示,假设由(t, v)边走到了v,v有三个邻居 x1 x2 x3, 其中x1与t邻接,则v到x1的概率不变,x2 与x3都不与t邻接,则v到x2的概率为原有的概率除以q,v到t的概率则是原有的概率除以p,用公式描述就如下:
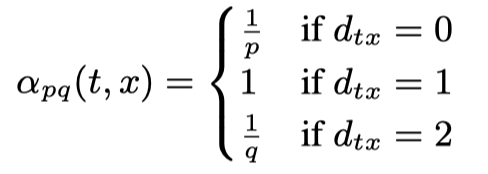
这里的d_tx就是t与x在图上最短距离,d_tx等于0说明x就是t,d_tx等于1说明t和x邻接,d_tx等于2就是t和x不邻接,从这里其实就可以看出来两个超参数作用了,p就是控制重复访问已访问节点的概率(Return parameter),q就是控制游走是偏DFS还是偏BFS(In-out parameter),经过这种有偏游走产生序列过后,就和DeepWalk一样了直接跑skipgram model来获取节点的embedding了。
除了有偏游走以外,node2vec还引入了alias sampling来提高计算效率,alias sampling是一种可以在O(1)时间复杂度按照指定概率分布来采样的算法,node2vec作者在进行随机游走之前会执行一个预计算来获取alias_nodes和alias_edges, alias_nodes存每个顶点决定下一个访问的点所需要的alias表,而alias_edges则存由(t, v)边访问到v的时候决定下一个访问点所需要的alias表,在作者给出的Python代码中preprocess_transition_probs函数就描述了这个预计算的过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
def preprocess_transition_probs(self): ''' Preprocessing of transition probabilities for guiding the random walks. ''' G = self.G is_directed = self.is_directed alias_nodes = {} for node in G.nodes(): unnormalized_probs = [G[node][nbr]['weight'] for nbr in sorted(G.neighbors(node))] norm_const = sum(unnormalized_probs) normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs] alias_nodes[node] = alias_setup(normalized_probs) alias_edges = {} if is_directed: for edge in G.edges(): alias_edges[edge] = self.get_alias_edge(edge[0], edge[1]) else: for edge in G.edges(): alias_edges[edge] = self.get_alias_edge(edge[0], edge[1]) alias_edges[(edge[1], edge[0])] = self.get_alias_edge(edge[1], edge[0]) self.alias_nodes = alias_nodes self.alias_edges = alias_edges return |
Practice
在了解了node2vec的基本原理过后,具体实践的时候就碰到了一些问题,最关键的就是如果输入的图很大,那么node2vec的预计算求alias_nodes和alias_nodes就会非常吃内存,其实主要是算alias_edges这一步,如果涉及到了千万级别的边,可能需要的内存就是百G级别,大部分实现都会在这一步跑着很困难,多番尝试无果之后,只能选择自己造轮子了,于是就实现了一版基于LRU Cache的alias_nodes 和alias_edges,在访问到当前节点或当前边的时候首先去查LRU Cache,如果命中的话就直接取算好的,没有的话就算一个alias表并写入到LRU Cache里面,这样就可以控制住内存了。第一个版本是用Python实现的,因为Python对多线程计算并不友好,多进程通信成本又太高,所以只能多进程然后各个进程维护一个LRU Cache,可这样只是解决了燃眉之急,毕竟如果有20个进程的话就需要有20个LRU Cache,随着进程数的增加也会浪费不少内存空间并且降低Cache命中率从而降低计算效率,最终还是用C++写了一个多线程版本,测试了一下,跑一个2.3w节点2300w边的图,开二十个线程只需要10G内存跑两个小时,总算是舒坦了,代码也开源在了github(https://github.com/razrLeLe/fastwalk),全部都是用标准库实现,开箱即用,欢迎PR or Star~

最后,用一盘产自家乡的清炒红菜苔来祝愿家乡早日脱离疫情:
